Real-time data exploration with slices
Two months ago, we rolled out a major new feature for Lokad: our first bit of real-time data exploration. This feature is codenamed dashboard slicing, and it took us a complete overhaul of the low-level data processing back-end powering Envision to get it done. With dashboard slices, every dashboard becomes a whole dictionary of dashboard views, which can be explored in real-time with a search bar.
For example, by slicing a dashboard intended as a product inspector, which gathers in one place all the information about a product - including probabilistic demand and lead time forecasts for example - it is now possible to switch in real-time from one product to the next.
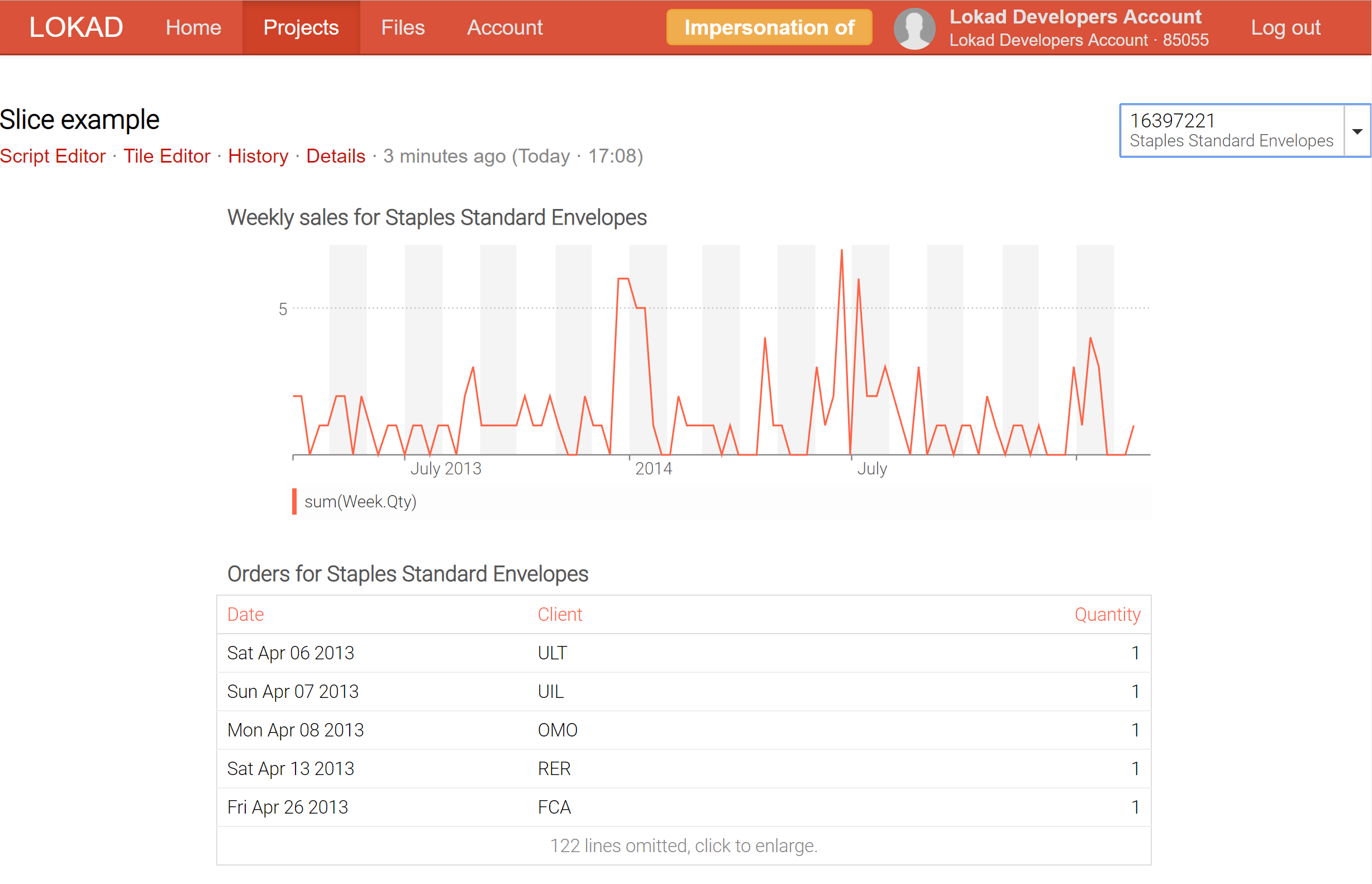
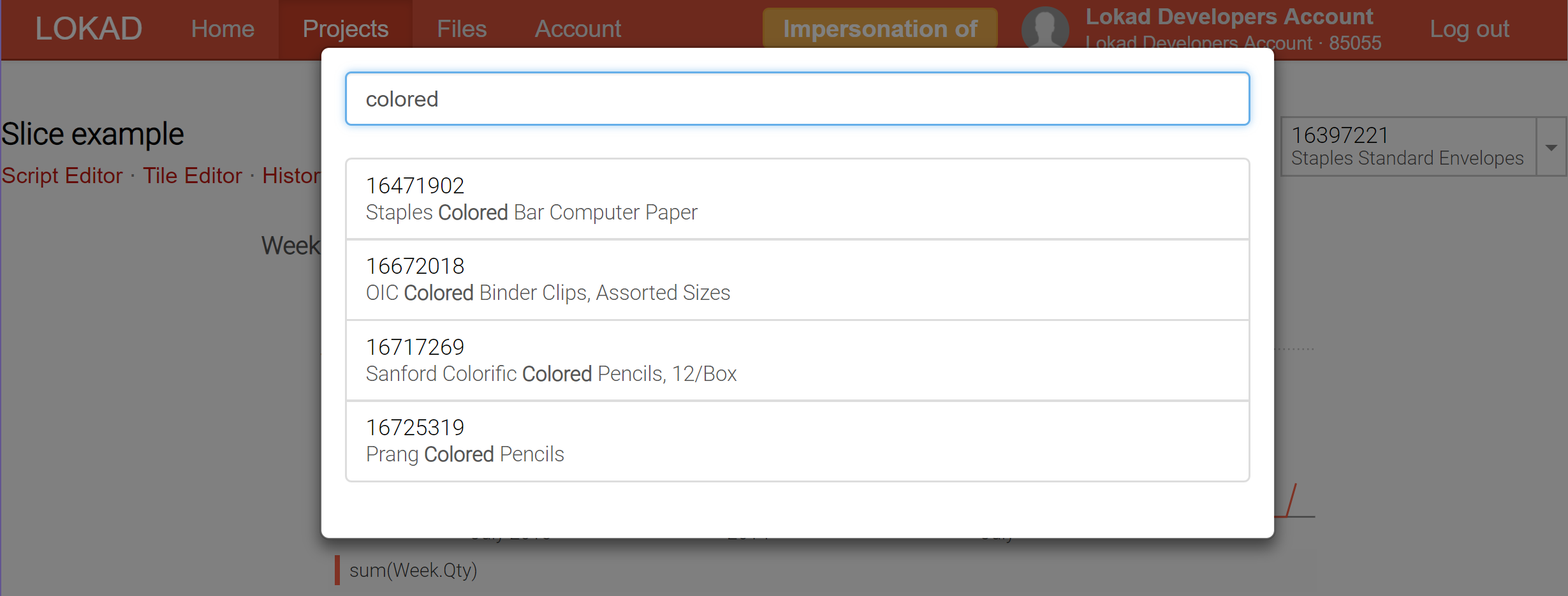
At present, Lokad supports up to 200,000 slices (aka dashboard views) to be produced for a single dashboard; and those slices can be displayed in real time through the selector, which comes with a real-time search feature in order to facilitate the exploration of the data. Unlike business intelligence (BI) tools, those slices can contain highly complex calculations, not merely slice-and-dice over an OLAP cube.
When it comes to data crunching and reporting there are typically two camps: online processing and batch processing. Online processing takes a feed of data, and it is typically expected that everything displayed by the system is always fresh: the system is not lagging more than a few minutes, sometimes no more than a few seconds behind the reality. OLAP cubes, and most of the tools referred to as business intelligence fall into this category. While real-time 1 analytics are highly desirable, not only from a business perspective (fresh data is better than stall data), but also for an end-user perspective (performance is a feature), they also come with stringent limitations. Simply put, it is exceedingly hard to deliver smart analytics2 in real-time. As a result, all online analytical systems come with severe limitations when it comes to the type of analytics that can be carried by the system.
On the other hand, batch processing is typically executed on a scheduled basis (e.g. daily runs) while all the historical data (or a sizeable portion of it) is input. The freshness of the results is limited by the schedule frequency: a daily batch always gives you results reflecting the situation of yesterday, not the situation of today. As all the data is available from the start, batch processing is ideal to perform all sorts of computing optimizations that can vastly increase the overall computing performance of the process. As a result, through batch processing it is possible to execute entire classes of complex calculations that remain beyond reach when considering online processing. Also, from an IT perspective, batch processing tends to be a lot easier both to implement and to operate 3. The primary downside of batch processing being the very delay imposed by the batched nature of the process.
As a software platform, Lokad is definitively in the batch processing camp. Indeed, while Quantitative Supply Chain optimization needs a high degree of reactivity, there are many decisions that do not require instant reactivity, for example deciding whether to produce an extra pallet of products, or deciding whether it’s time to lower the price in order to liquidate a stock. For these decisions, the prime concern is to take the best decision possible, and if this decision can be measurably improved by spending one more compute hour on the case, then it’s nearly guaranteed that this one extra computer hour will be a good investment 4.
Thus, Envision is designed around a batch processing perspective. We have quite a few tricks up our sleeves to make Envision very fast even when dealing with terabytes of data; but at this scale we are talking about getting results within minutes, not under a second. Actually, due to the highly distributed nature of the Envision computation model, it’s challenging for Lokad to complete the execution of any Envision script is less than 5 seconds or so - even when there are only a few megabytes of data involved. The more distributed a system, the more internal inertia there is to synchronize all the parts. More scalability is the enemy of lower latency.
A few years ago, we introduced the notion of entry forms in Envision: a feature that lets you add a configurable form on the dashboard, which becomes an input accessible from the Envision script. For example, through this feature, it was straightforward to design a dashboard intended as a _product inspector_displaying all the relevant information afferent to the specified products Unfortunately, in order to get the dashboard aligned with newly entered form value, the Envision script had to be re-executed, leading to seconds of delay to get the refreshed results; a duration that was unacceptably long for data exploration.
The dashboard slices (check out our technical documentation) represent our attempt to get the best of both worlds: online and batch processing. The trick is that Lokad can now compute in batch a vast number of slices (each slice can reflect a product, a location, a scenario, or a combination of all those things) and let you switch from one slice to another in real-time, which is possible because everything has been precomputed. Naturally, precomputing a large number of slices is more expensive computationally, but not as much as one might think. It’s typically cheaper for Lokad to compute 10,000 slices at once, rather than perform 100 independent runs, each run dedicated to a single slice.
Through slices, Lokad is gaining business-intelligence-on-steroid capabilities: not only is it possible to explore many different views (eg. products, locations, time periods) in real-time, but without any of the usual restrictions of online processing architectures.
-
In a distributed system, there is no such thing as “real time”. The speed of light itself is putting hard limits on the degree of synchronization of a system spreading over several continents. Thus, this terminology is somewhat abusive. Yet, if the overall latency is under a second or so, it’s typically acceptable to qualify a data-crunching app as “real-time”. ↩︎
-
Even advanced real-time data processing systems like the ones used for autonomous driving carefully avoid any learning operation when operating in real-time. All the machine learning models are precomputed and static. ↩︎
-
The typical implementation of a batch process consists of moving flat files around, which is a basic feature supported by pretty much every single system nowadays. Then, from an operations perspective, if one component of the batch process suffers a transient downtime, a simple retry-policy usually solves the problem. In contrast, online systems tend to behave badly when one component goes down. ↩︎
-
At the present date, one hour of computation over a modern CPU typically costs less than $0.02 when using pay-as-you-go over the dominant cloud computing platforms. Thus, as long as the benefits generated by a single better supply chain decision is worth a lot more than $0.02, it makes sense to invest this one hour of computation. ↩︎

